0:00 0:00
Article
Claude Codeで長い会話や大きなリポジトリを扱うコンテキスト管理術
数十万行規模のリポジトリや、半日以上続く長い会話でClaude Codeの精度を保つための具体策を整理します。読ませる範囲の絞り込み、中間成果物、サブエージェント分離、セッション再開、CLAUDE.md設計までを実務目線で扱います。
数十万行のモノレポ、半日続く会話、3桁のファイルを跨ぐリファクタ。こういう「大きい」状況でClaude Codeを素直に使うと、応答品質が露骨に落ちます。Best Practicesも「context window fills up fast, performance degrades as it fills」と明言しています。本記事では、大きな会話と大きなリポジトリの両方で精度を保つための具体策を、運用順に整理します。
結論:「読ませない」「忘れる」「分ける」の3軸で設計する
大規模対応で効くのは新機能の発見ではなく、運用ルールの徹底です。次の3軸でメニューを揃えます。
- 読ませない:
@参照は最小、CLAUDE.mdは200行以内、.gitignore/claudeMdExcludesで除外、deny ruleで物理的に塞ぐ - 忘れる:
/clear/compact <instructions>/rewindEsc Escを局面で使い分け、kitchen sinkセッションを切る - 分ける:サブエージェントに調査を委譲、
--continue/--resumeでセッションを跨ぐ、長期作業はNOTES.mdで引き継ぐ
「読ませない」全体像は「Claude Codeに必要な情報だけ渡すコンテキスト設計」、「忘れる」の手順は「Claude Codeでコンテキストウィンドウを無駄にしない運用方法」で扱っています。本記事は両者を大規模リポジトリ/長時間セッションという条件で組み合わせ直すのが主眼です。
大きなリポジトリで最初に決める3点
1. ルートCLAUDE.mdは「触る場所の地図」だけにする
200行以内の鉄則は、モノレポでも同じです。詰め込まず、「どこに何があるか」「触ってはいけない領域」「ローカルルールの所在」を入口だけ書きます。
# CLAUDE.md(ルート)
## 構成
- apps/web : Next.js 15 / フロントエンド
- apps/api : Hono / APIサーバー
- packages/ui : 共通UI(Storybook)
- packages/db : Prisma + マイグレーション
- infra/ : Terraform(人間オペレーションのみ)
## ローカルルール
- フロント: @apps/web/CLAUDE.md
- API: @apps/api/CLAUDE.md
- DB変更: @packages/db/CLAUDE.md
## 触らないでください
- infra/ 配下(人間が手作業で適用)
- generated/ 配下(コード生成出力)サブパッケージ固有のルールはそれぞれのCLAUDE.mdに置きます。pathsフロントマターで「触っているディレクトリのCLAUDE.mdだけロード」させると、無関係な領域のルールが混入しません。CLAUDE.md本体の構造は「CLAUDE.mdテンプレート完全版」を参照してください。
2. .gitignoreとclaudeMdExcludesの二重防御
大きなリポジトリには生成物・成果物・サードパーティが大量に紛れています。.gitignore済みでも、@やReadで読みに行こうとすると無駄なI/Oが発生します。設定で物理的に塞ぐのが効きます。
{
"claudeMdExcludes": [
"node_modules/**",
"dist/**",
"build/**",
".next/**",
"coverage/**",
"**/*.snap",
"**/__generated__/**",
"generated/**"
]
}副作用のある領域(マイグレーション・本番DB接続)にはdeny ruleを追加し、ファイル単位で読み書きを止めます。「Claude Codeに秘密情報を渡さないための実践ルール」の3層防御をベースに、大規模では範囲を広めに張るのがコツです。
3. ripgrepで「読み込みすぎ」を抑える
@directory/で丸ごと参照すると、サブツリー全体が読み込み対象になります。大規模では「先にrgで候補を絞り、必要箇所だけ@fileで渡す」が基本です。
rg -l 'createCheckoutSession' apps packages ヒットしたファイルの中から1〜3個だけClaudeに渡します。AIに「grep -lで関連箇所を絞ってから読んで」と依頼してもよいですが、初期サーチくらいは人間が先回りした方が確実に速く、コンテキストも節約できます。
大きな会話を腐らせない4つの操作
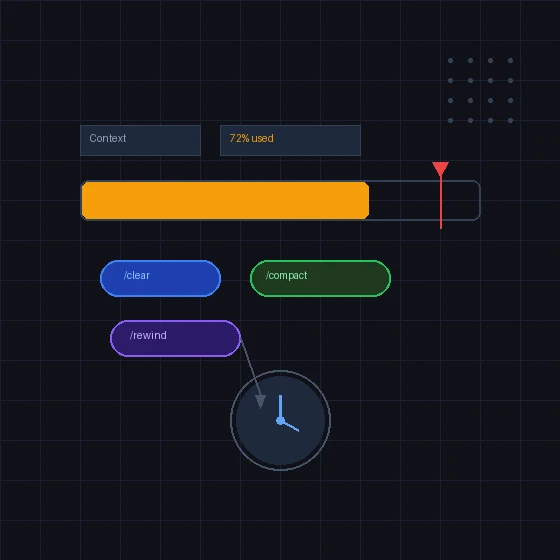
1. /contextで常に「使用量」を見る
/contextを1時間に1回でも叩いて、何がトークンを取っているかを目視します。CLAUDE.md・MCPツール定義・履歴・@で読んだファイル全文・Bash標準出力の内訳が見えます。これを見てから対処を決めるのが、勘で/clearするより効率的です。
2. /clear vs /compact <instructions> vs Esc Esc
3つは似て非なる操作です。使い分けの目安は次のとおりです。
| 操作 | 用途 | 残るもの |
|---|---|---|
/clear | 別タスクへ完全に切り替える | CLAUDE.mdとシステムプロンプトのみ |
/compact "X を保持して" | 同じ作業を続けるが履歴が長くなった | 要約された会話+保持指示の部分 |
Esc Esc(チェックポイントから要約) | 直前のN分の探索が無駄だった | 指定地点までの会話+それ以降の要約 |
/rewind | 特定の地点まで戻りたい | 指定チェックポイント以前のすべて |
「2回連続で同じバグ修正に失敗したら/clearして書き直す」「タスク切り替え時は必ず/clear」をチーム規約にしておくと、kitchen sinkセッションを未然に防げます。
3. 中間成果物をNOTES.mdに書き出す
長い調査の途中結果は、Claudeの記憶ではなくファイルに書かせます。
依頼:
apps/api/src/billing/ の調査結果を NOTES.md に書き出してください。
- 主要エンドポイント
- 課金計算のエントリポイント関数
- 触ると怖い箇所(テスト不在・複雑な状態遷移)
以降の作業はこの NOTES.md を参照して進めます。セッションを跨いでも参照でき、人間レビューもできます。CLAUDE.mdにNOTES.mdの位置を書いておくと、次セッションでも自動的に読まれます。
4. --continue/--resumeでセッションを跨ぐ
数日に渡る作業は、1セッションに詰め込まず、毎日新しいセッションでclaude --continueまたはclaude --resumeを使います。前日の会話履歴を持ち越せるので、NOTES.mdと組み合わせると「履歴は要約」「事実はNOTES.md」の二重化で精度が安定します。
claude --continue 特定の過去セッションを呼び戻すなら--resumeです。
claude --resume サブエージェントで調査を分離する
大きなリポジトリで「全体を把握する」依頼を1つの会話でやると、必ずコンテキストが破綻します。読み取り専用のサブエージェントに調査だけ委譲し、要約だけ親に返すパターンが基本になります。
Explore サブエージェントに依頼してください:
「apps/api/src/billing/ 配下の主要エンドポイントを列挙し、
各エンドポイントが呼ぶ関数の入口だけ NOTES.md にまとめる。
実装の中身は読まないでよい。」ExploreはHaikuベース・読み取り専用なので、コストを抑えながら広く浅く読みに行けます。設計の使い分けは「Claude Codeのサブエージェントとは?使いどころと注意点」、コスト管理は「Claude Codeのトークン消費を抑えるサブエージェント運用」を参照してください。
大規模リファクタの進め方
複数ファイルを横断するリファクタを大規模リポジトリでやるときは、4ステップを愚直に踏みます。
- 影響範囲調査:サブエージェントで
rg/grepして触る範囲のリストを出す - 計画:Plan Modeで「型定義→実装→呼び出し元→テスト」の順序を確定
- 1ファイルずつ変更+テスト+中間コミット:全体ビルドは1回ずつ走らせず、変更ファイル単位で確認
- ロールバック方針の確認:
git restore/git reset --soft//rewind/git worktreeのどれを使うか先に決める
詳細手順は「Claude Codeで複数ファイルの変更を安全に進めるコツ」で扱っています。本記事では「中間コミット粒度を小さくする」「ロールバック先を1ファイル単位に保つ」の2点が大規模ならではのコツです。
失敗パターン5種と対処
| 症状 | 原因 | 対処 |
|---|---|---|
| 提案が他パッケージのルールを破る | ルートCLAUDE.mdに全部詰めた | サブパッケージCLAUDE.mdに分割+paths |
| 回答が遅く、修正が雑になる | @directory/で大量読み込み | rgで先に絞ってから@file単発 |
| 過去の決定を忘れる | 履歴だけに頼った | NOTES.mdに事実を書き出し、CLAUDE.mdから参照 |
| 2時間後に方針がブレる | 長時間1セッション | 1〜2時間で/clear、別タスクは新セッション |
| 同じバグを何度も提案 | autocompactで重要情報が落ちた | /compact "失敗した修正案: ..." を保持を明示 |
「遅さ」の網羅的な切り分けは「Claude Codeが遅いときに確認する設定・コンテキスト・ファイル量」を参照してください。
1日あたりの運用テンプレ
長期作業ではタイムボックスが効きます。次の流れをデフォルトにします。
- 朝(10分):前日の
NOTES.mdを読み、今日触るパッケージのCLAUDE.mdを音読 - 各タスクの開始時(5分):Plan Modeで計画レビュー、影響範囲をrgで先に把握
- 作業中(60〜90分):1セッションに1主題、
/contextを30分に1回見る - 切り替え時:
/clearして別タスクへ。終わったタスクはNOTES.mdに1〜3行で要約 - 終業(10分):
NOTES.mdに翌日への申し送りを書き、claude --continueの起点を残す
詳細な1日の枠組みは「Claude Codeを使った1日の開発フロー」を併読してください。
大規模対応チェックリスト
- ルートCLAUDE.mdは200行以内で「地図」だけにした
- サブパッケージCLAUDE.mdを
pathsで分離した -
claudeMdExcludesに生成物・成果物・サードパーティを入れた - deny ruleで本番DB・マイグレーション・秘密情報パスを物理的に塞いだ
-
@directory/での丸読みをやめ、rgで先に絞ってから@fileで渡す運用にした -
/contextを定期的に見る習慣を導入した -
/clear/compactEsc Esc/rewindの使い分けを決めた - 調査はExplore等のサブエージェントに委譲し、
NOTES.mdに要約だけ持ち帰る - 長期作業は
claude --continue/--resumeでセッションを跨ぐ - 1セッション1主題、kitchen sinkを避けるルールをチームで合意した
次に読むおすすめ記事:
- 「Claude Codeに必要な情報だけ渡すコンテキスト設計」:3層モデルとコンテキスト予算
- 「Claude Codeでコンテキストウィンドウを無駄にしない運用方法」:
/clear//compact//rewindの使い分け - 「Claude Codeのサブエージェントとは?使いどころと注意点」:調査委譲によるコンテキスト分離