0:00 0:00
Article
Claude Codeに大きなタスクを渡す前にやる「分解」の手順:親子タスク・依存関係・完了条件の作り方
Claude Codeに大きめの開発タスクをそのまま投げると、途中で計画が崩れたり、無関係な変更が混じったりしがちです。親タスク→子タスクへ分解し、依存関係と完了条件をはっきりさせる実践的な手順を、公式ベストプラクティスに沿って整理します。
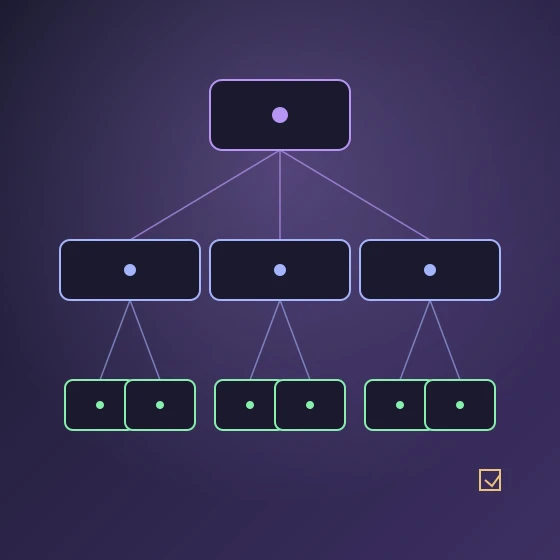
結論:Claude Codeに渡す前に「親タスク→子タスク→完了条件」の3段で分解する
Claude Codeに大きめの開発タスクを丸ごと投げると、調査と実装が混ざって計画が崩れたり、関係ないファイルに手が入ったりしがちです。これを防ぐ一番効く方法は、依頼する前に自分で「親タスク→子タスク→完了条件」の3段に分解しておくことです。
- 親タスク: 最終的に何が達成されれば終わりか(ユーザー価値や機能単位)
- 子タスク: 1回のセッションで終わる粒度(1〜2ファイル/30分〜2時間程度)
- 完了条件: 子タスクごとに観測可能な終了基準(テスト・コマンド・スクリーンショットなど)
公式のベストプラクティスでも、**「explore first, then plan, then code」**と、context窓を埋めすぎないことが繰り返し強調されています。タスク分解は、この2つを依頼側で担保するための最初の道具です。
本記事は、依頼文の型を示すプロンプトの基本構造や、計画フェーズを強制するPlan Modeプロンプトの手前で行う「依頼設計」にフォーカスします。
なぜ大きなタスクをそのまま投げると失敗するか
Claude Codeの裏側では、会話履歴・読んだファイル・コマンド出力のすべてがコンテキストに積み上がっていきます。公式ドキュメントは**「LLM performance degrades as context fills」**と明言しており、コンテキストが埋まるほど精度が下がる前提で運用する必要があります。
大きなタスクを丸投げしたときに起きる典型的な失敗は次のとおりです。
- 調査→実装→テスト→ドキュメントをすべて1セッションで回そうとしてコンテキストが溢れる
- 途中で方針が変わったときに、前の試行錯誤がゴミとして残り続ける
- 複数ファイルへの変更が1コミットにまとまり、レビューも差し戻しも巨大化する
- 「〜も一緒に直しておいて」が連鎖して、本来のスコープが崩壊する
分解せずに投げるのは、人間のジュニアに「この機能よろしく」と口頭で伝えるのと同じで、ちゃんと進むかどうかは運次第になります。
STEP1: 親タスクを1文で書く
最初にやるのは、親タスクを1文で書き切ることです。ここが曖昧なまま分解に進むと、子タスクも曖昧になります。
悪い例と良い例を比べると差が分かりやすいです。
悪い: 認証まわりを良くする
良い: パスワード認証にメールアドレス検証を追加し、未検証ユーザーは /login でエラー表示する良い例は観測可能な終わりの絵(「/loginでエラーが出る」「未検証ユーザーが分かる」)が含まれています。1文で書けないうちは、まだ親タスク自体が曖昧なので、まず要件を整理してからClaude Codeに触れます。
親タスクに含めるべき要素
| 要素 | 例 |
|---|---|
| 何を | メール検証フロー |
| 誰のために | 新規登録ユーザー |
| どこに | src/auth/ 配下 |
| 何が満たされたら終わりか | 未検証ユーザーは/loginで専用メッセージが出る |
ここまで揃うと、次のSTEP2以降がただの作業に変わります。
STEP2: 子タスクに割って依存関係を描く
親タスクを、1セッションで終わる粒度の子タスクに割ります。Claude Codeの場合、ひとつのセッションで読ませるファイル量と生成量が多すぎるとコンテキストが圧迫されるので、次の目安が現実的です。
- 変更するファイル: 1〜3ファイル
- かかる時間: 30分〜2時間
- テストがすでにあるか、新規で1〜2件追加できる
たとえば先の認証の例なら、こう割れます。
親: メール検証フローの追加
子1: users テーブルに email_verified_at 列と migrate を追加
子2: 登録時に検証メールを送るサービス関数を追加
子3: /verify エンドポイントでトークンを検証し email_verified_at を埋める
子4: /login で email_verified_at 未セットのユーザーにエラーを返す
子5: UI 側で /login のエラー文言を表示このあと依存関係を描きます。子1 → 子2 → 子3 → 子4 → 子5 のように線形のこともあれば、子1 → 子2 と 子3 は並列 のように分岐のこともあります。依存関係を書き出すと、並列に進められる仕事が可視化され、同時に先に終わらせないといけないブロッカーも見えます。
依存関係の書き方テンプレート
## 子タスク
- [子1] DB: users.email_verified_at を追加
- [子2] 送信: 新規登録時に検証メール送信
- [子3] 検証: /verify エンドポイント
- [子4] 拒否: /login で未検証ユーザーを弾く
- [子5] UI: /login にエラー文言
## 依存
- 子1 → 子2
- 子1 → 子3
- 子3 → 子4
- 子4 → 子5このメモは、そのままCLAUDE.mdや作業用ブランチのPR下書きに貼り付けても役立ちます。
STEP3: 子タスクごとに完了条件を書く
受け入れ条件の作り方で整理したとおり、完了条件はプロセスではなく結果で書きます。Claude Codeは、検証手段があると成功率が大幅に上がります。公式ベストプラクティスでも、「Give Claude a way to verify its work」は単体で最も効果が高い施策だと紹介されています。
子タスクごとに次のような形で書いていきます。
## 子1: users.email_verified_at 追加
### 完了条件
- migration ファイルが `db/migrations/` に追加されている
- `npm run db:migrate` が成功する
- users テーブルに `email_verified_at` (nullable timestamp) が存在する
- `npm test -- tests/models/user` が緑ポイントは、依頼を受けたClaude Code自身がチェックできる条件にすることです。人間の主観(「きれいなコード」「ちゃんと動く」)ではなく、コマンド実行や型チェックなどに落とします。
STEP4: 並列化できるところを見極める
子タスクが揃い、依存関係が書けていれば、並列化できる部分が見えてきます。並列化には2つのやり方があります。
- 人間が複数タスクを順に回す: 1つのセッションで子1、別セッションで子3、とタスクを切り替える
- サブエージェントに調査を任せる: 1セッションの中で、調査をサブエージェントに出して本線の実装と並行させる
並列化は万能ではありません。次のような場合はあえて直列にするほうが安全です。
- DBスキーマやAPIシグネチャなど、後段が強く依存する変更
- コンフリクトしやすいファイル(共通設定、ルーターなど)への変更
- 不確実性が高く、前段の結論で後段の設計が変わる可能性がある
公式ドキュメントでもsubagentsは**「探索やログ漁りをメインの会話から分離する」**のが本来の使い方と説明されています。分解できていないタスクをサブエージェントに丸投げしても、無駄な並列化が増えるだけなので注意します。
STEP5: Claude Codeに渡す順序を決める
ここまでくれば、あとはどの順序でClaude Codeに渡すかを決めるだけです。基本は次の順です。
- DB・型・共通IFなど下流に影響するもの
- 単独で動く機能(送信、検証)
- それらを束ねる導線(エンドポイント、UI)
- テストとドキュメント
各子タスクを渡すときは、プロンプトの基本構造で示した7ブロック(目的・背景・入力・制約・出力・完了条件・禁止事項)に沿って書くと安定します。調査が必要ならPlan Modeで子タスクの計画を先に作らせ、承認してから実装に移ります。
セッション間で情報を持ち越すコツ
子タスクごとにセッションを分けると、前のセッションで分かったことをどう引き継ぐかが課題になります。現実的な選択肢は次の3つです。
CLAUDE.mdに安定したルール(APIシグネチャ、命名、禁止事項)を書く- 作業メモ(
NOTES.mdなど)に「前回までの結論」を書いて@NOTES.mdで引き渡す claude --continueやclaude --resumeでセッション自体を復帰させる
セッション復帰は便利ですが、古い試行錯誤も戻ってきてコンテキストを食うため、長時間回したセッションよりは「新しいセッション+メモ渡し」のほうが精度が出ることが多いです。
AI丸投げを避けるための観点
最後に、タスク分解という作業自体を「Claude Codeに考えてもらえばいいじゃん」と丸投げしないための観点を3つ挙げておきます。
- 価値判断は人間が持つ: どの機能を先に出すか、どの品質で妥協するかはビジネス判断で、AIに委ねる性質のものではありません。
- アーキテクチャ境界は人間が決める: ファイル配置、責務の切り方、DB設計は、将来の保守性に直結するので、人間のレビュー前提で扱います。
- 失敗時の戻しも人間が持つ: 途中で方針変更するとき、どこまで捨ててどこから続けるかの判断は、AIよりも人間のほうが早く正しく決められます。
分解作業は人間が行い、実装は分解済みの単位をClaude Codeに任せる、という役割分担が今のところ一番安定しています。
依頼前チェックリスト
子タスクをClaude Codeに渡す前に、これだけは確認してから投げると失敗がぐっと減ります。
- 親タスクが1文で書けていて、終わりの絵が観測可能
- 子タスクが1〜3ファイル/30分〜2時間の粒度
- 子タスクごとの完了条件がコマンドで検証できる形
- 依存関係が線で描けていて、ブロッカーが分かる
- 並列化してよい部分と、直列にすべき部分が区別されている
-
CLAUDE.mdに共通ルール(禁止事項、命名、テストコマンド)が揃っている
このチェックを通してからプロンプトの基本構造に流し込めば、Claude Codeの成功率は体感で別物になります。
次に読む
- Claude Codeに伝わるプロンプトの基本構造 — 子タスクを渡すときの依頼文フォーマット
- Claude Codeに「計画してから実装」させるプロンプト例 — 子タスクごとに計画フェーズを強制するやり方
- Claude Codeの成功率を上げる制約条件と受け入れ条件の作り方 — 完了条件を粒度別に書き分けるテンプレ