0:00 0:00

Article
DeepSeek-V4登場:100万トークン文脈とハイブリッド注意機構でエージェント実用域へ
DeepSeekが2026年4月24日に公開したDeepSeek-V4は、100万トークン文脈とKVキャッシュを2%まで圧縮するハイブリッド注意機構で、エージェント用途の実用化を狙う大型アップデートです。
100万トークン文脈をエージェント用途に最適化したDeepSeek-V4
DeepSeekは2026年4月24日、フラッグシップモデルの大型アップデートにあたるDeepSeek-V4をHugging Face上で公開しました。最大の変更点は、100万トークンまで拡張された文脈長と、それをエージェントワークロードで実用的に使えるよう最適化したハイブリッド注意機構の採用です。
公式発表では、長文脈をただ「読める」のではなく**「エージェントが本当に使える形で」読める**ことに焦点を当てています。具体的には、ツール呼び出しを跨ぐ推論の継続、XMLベースのツールスキーマ、推論コストを抑える注意機構の刷新が同時に投入されました。
ベースモデルとインストラクションモデルが同時に提供され、いずれもFP4/FP8の量子化版が用意されています。重みはHugging Face Hub経由で取得できます。
2つのチェックポイント:Pro 1.6Tと Flash 284B
V4は2系統のサイズで提供されます。フラッグシップのDeepSeek-V4-Proは総パラメータ1.6T、アクティブ49Bという大型MoE構成です。一方のDeepSeek-V4-Flashは総284B、アクティブ13Bと軽量で、レイテンシとコストを優先したいシナリオを想定しています。
両モデルともインストラクション版とベース版が用意され、研究用途と本番投入の両面に対応します。エージェント運用を主な狙いに置くため、Pro系は「Max」と呼ばれる強化版でベンチマーク値が公開されており、Flash系は「軽量だが文脈は同じ100万トークン」という位置取りです。
DeepSeekは公式ブログで、これら2モデルが同じトークナイザー・同じツール呼び出し規約を共有することを明示しており、開発者は段階的にFlashからProへ切り替える設計を取りやすくなっています。
画像引用元: Hugging Face Blog
ハイブリッド注意機構:KVキャッシュを2%まで圧縮
V4の中核となる技術が、**Compressed Sparse Attention(CSA)とHeavily Compressed Attention(HCA)**を組み合わせたハイブリッド注意機構です。標準的なグループ化クエリ注意(GQA)と比較して、KVキャッシュのメモリ消費を2%程度まで削減できると発表されています。
KVキャッシュは長文脈モデルにとって最大のコスト要因の一つで、これを大きく圧縮できれば、同じハードウェアでより長い文脈と多数の並列セッションが回せるようになります。エージェント用途は1セッションあたりの読み書きが多く、KVが膨らみやすいため、この圧縮は実装上のインパクトが大きい部分です。
CSAとHCAはレイヤーごとに使い分けられ、重要度の高い情報はCSAで保持しつつ、長尾の文脈はHCAで強く圧縮する設計とされています。論文や技術レポートも順次公開予定とDeepSeekは案内しています。
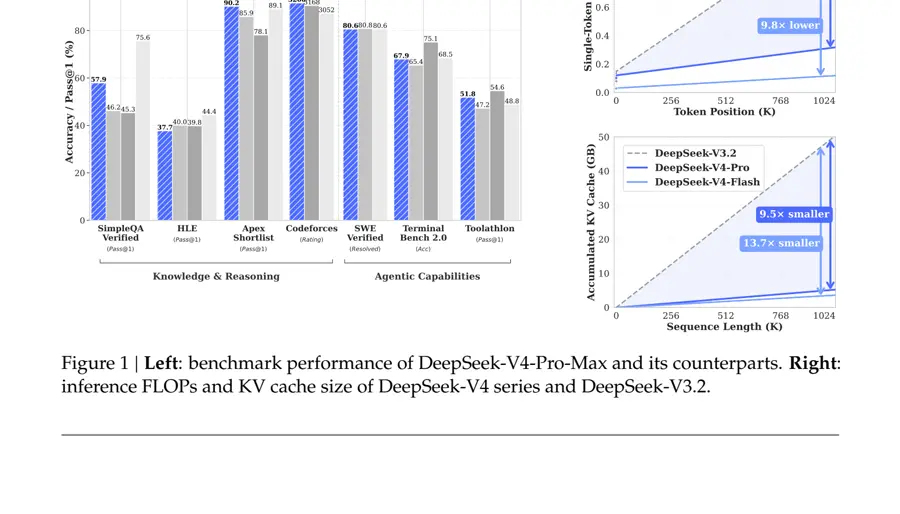
ベンチマーク:Terminal BenchやSWE Verifiedで競合水準
公式に公開された主要ベンチマークでは、DeepSeek-V4-Pro-Maxが次の数字を出しています。
| ベンチマーク | スコア |
|---|---|
| Terminal Bench 2.0 | 67.9 |
| SWE Verified | 80.6 |
| MCPAtlas Public | 73.6 |
| Toolathlon | 51.8 |
| 内部R&Dコーディング | 67%(Sonnet 4.5: 47%、Opus 4.5: 70%) |
| MRCR 8-needle Retrieval(256K) | 0.82 |
| MRCR 8-needle Retrieval(1M) | 0.59 |
注目したいのは、**100万トークン文脈での検索精度(MRCR)**を公式が明示している点です。256Kでは0.82と高水準を保ち、1Mでも0.59を確保しており、長文脈で精度がどこまで落ちるかを利用者が判断できる材料が示されています。コーディング能力面では、内部評価でAnthropic ClaudeのSonnet 4.5を上回り、Opus 4.5に肉薄する結果が示されています。
ツール呼び出し前提の後段学習:XMLスキーマと推論の継続
V4のもう一つの大きな変更は、エージェント運用を前提にした後段学習です。発表では、ツール呼び出しを跨いで推論を継続できる「interleaved reasoning」、ツール定義に専用トークンを割り当てるXMLベースのツールスキーマ、そして**DeepSeek Elastic Compute(DSec)**と呼ばれる推論基盤の最適化が並んでいます。
これらは、Model Context Protocol(MCP)のように外部ツールを束ねて使うエージェントワークロードで効くように設計されています。とくにXML形式のツール定義は、Claude Codeなど既存のエージェント基盤で見られる「タグ構造化プロンプト」とも親和性が高く、移植・併用がしやすい形を取っています。
DeepSeekは、これらの後段学習がMCPAtlasやToolathlonといったエージェント特化ベンチでスコアを押し上げたと述べており、長文脈拡張とツール用最適化の両輪で「エージェント時代のオープンモデル」を狙う姿勢を明確にしました。
まとめ:ローカルから検証できる選択肢が増えた
DeepSeek-V4は、100万トークン文脈・KV圧縮・エージェント特化後段学習を1リリースに同時投入した重要なアップデートです。クローズドモデルと正面から競合する性能を示しつつ、Hugging Faceで重みが配布されるため、検証や自前運用も視野に入ります。
オープンモデルでエージェント基盤を組みたいチームにとっては、Flashで実装と評価を回し、Proでスケールさせる段階的な投入計画が現実的になりました。今後公開される技術レポートで、CSAとHCAの内部仕様や量子化時の精度低下幅などが明らかになると、採用判断はさらにしやすくなりそうです。

DeepSeek-V4: a million-token context that agents can actually use
We’re on a journey to advance and democratize artificial intelligence through open source and open science.