0:00 0:00

Article
Google、70言語以上対応の音声合成モデル「Gemini 3.1 Flash TTS」を発表——テキスト内の自然言語タグで声色やテンポを制御
Googleは次世代テキスト音声合成モデルGemini 3.1 Flash TTSを発表しました。70以上の言語に対応し、テキスト中に埋め込む自然言語タグで声のスタイルやペースを細かく調整できます。
Gemini 3.1 Flash TTSとは何か
Googleは2026年4月15日、次世代のテキスト音声合成(TTS)モデル「Gemini 3.1 Flash TTS」を発表しました。70以上の言語に対応し、従来のTTSモデルと比較して、より自然で表現力の高い音声を生成できるとしています。
最大の特徴は「Audio Tags」と呼ばれる仕組みです。テキスト中に自然言語で書かれた指示を埋め込むことで、声のスタイル、話す速度、感情表現などを細かく制御できます。従来のSSMLタグのような機械的な記法ではなく、「落ち着いたトーンで」「少しテンポを上げて」といった平易な言葉で指定できるため、開発者以外にも扱いやすい設計です。
Audio Tagsによる音声制御の仕組み
Audio Tagsは大きく3つの使い方があります。1つ目は「Scene Direction」で、音声全体のムードを設定するものです。たとえばナレーション全体を「穏やかで親しみやすい口調」にしたいといった場面で使います。
2つ目は「Speaker-Specific Settings」で、複数の話者が登場するコンテンツで話者ごとに異なる声質やトーンを割り当てるものです。オーディオブックやポッドキャストの制作で、キャラクターごとの演じ分けを自動化できます。
3つ目は文中の特定箇所にインラインで指示を挿入する方法です。「この単語を強調して」「ここで間を空けて」といった局所的な制御が可能になり、ニュースの読み上げやeラーニング教材での利用が想定されています。いずれもAPIリクエストのテキスト内に直接記述するだけで動作するため、追加のパラメータ設定は不要です。
画像引用元: Google Blog
ベンチマーク結果とSynthID透かし
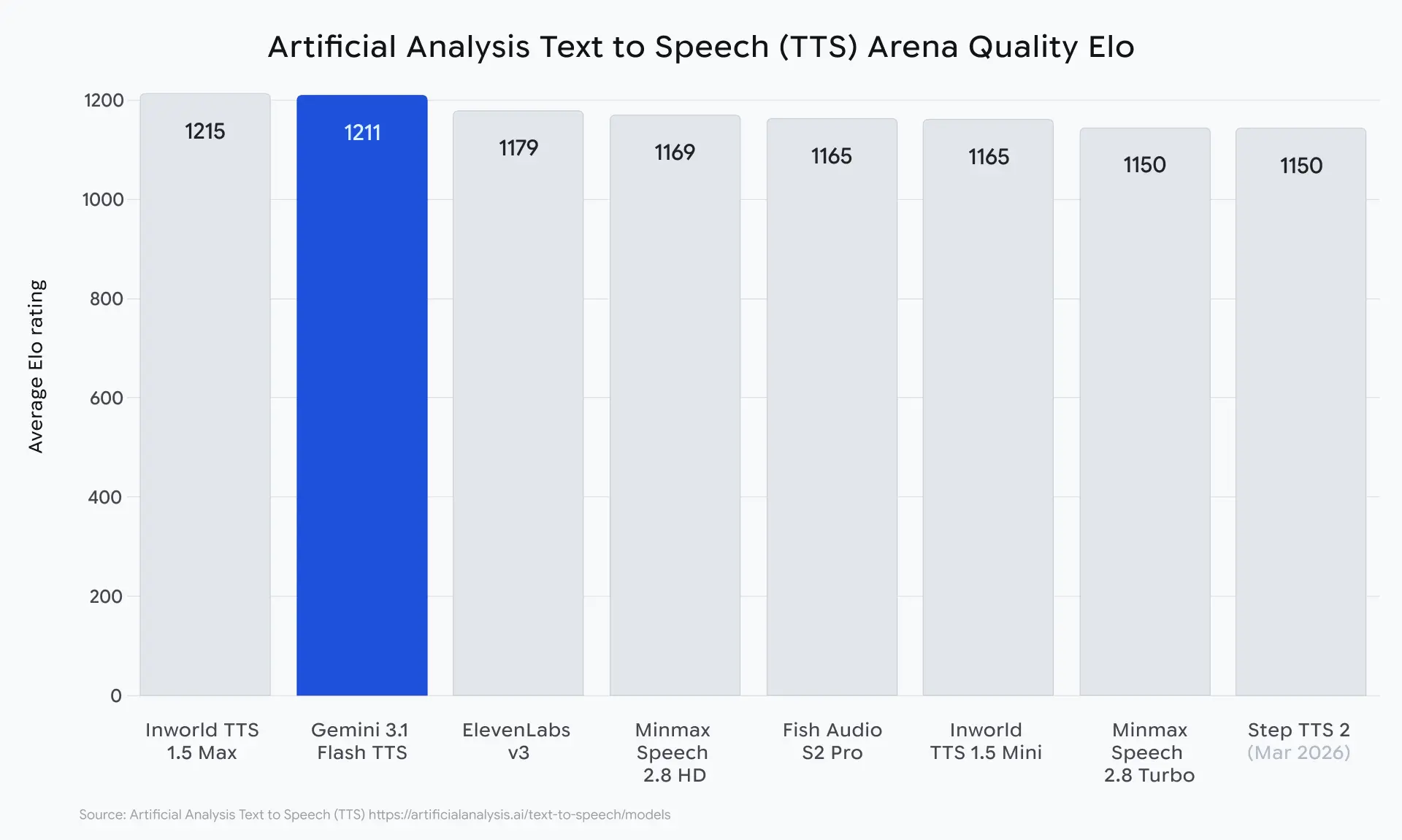
Googleによると、Gemini 3.1 Flash TTSはArtificial AnalysisのTTSリーダーボードでEloスコア1,211を記録しています。同リーダーボードではElevenLabs v3やInworld TTS 1.5 Maxといった競合モデルが上位に並んでおり、Gemini 3.1 Flash TTSはこれらと肩を並べる水準にあると位置づけられています。
セキュリティ面では、生成されたすべての音声にSynthIDの電子透かしが埋め込まれます。SynthIDはGoogle DeepMindが開発したAI生成コンテンツの識別技術で、音声がAIによって合成されたものであることを事後的に検証できます。ディープフェイク対策としてAI生成音声の出所を追跡できる仕組みを標準で組み込んでいる点は、商用利用を検討する企業にとって重要な判断材料になるでしょう。
開発者向けの提供チャネルと今後の展開
Gemini 3.1 Flash TTSは現在プレビューとして提供されており、Google AI StudioとGemini APIから開発者が試用できます。エンタープライズ向けにはVertex AIを通じた提供も予定されています。さらにGoogle VidsのWorkspaceユーザーにも順次展開されるため、動画制作のナレーション用途でもすぐに活用できるようになる見込みです。
APIからのコードエクスポート機能も備わっており、AI Studioで調整した音声設定をそのままアプリケーションに組み込めます。70以上の言語をカバーしている点はグローバル展開を行う企業にとって実用的で、多言語対応のカスタマーサポート音声や教育コンテンツの制作コストを大幅に下げられる可能性があります。

Gemini 3.1 Flash TTS: the next generation of expressive AI speech
Gemini 3.1 Flash TTS is now available across Google products.