0:00 0:00
Article
企業IT運用エージェントの新ベンチマーク『ITBench-AA』公開——最高でもClaude Opus 4.7の47%、全フロンティアモデルが50%未満
Artificial AnalysisとIBMは2026年5月27日、エージェントによる企業IT運用(まずSRE)を測る初のベンチマーク『ITBench-AA』を公開しました。Kubernetesインシデントの根本原因特定タスクで、最高スコアはClaude Opus 4.7の47%。全フロンティアモデルが50%未満という未飽和の難ベンチです。
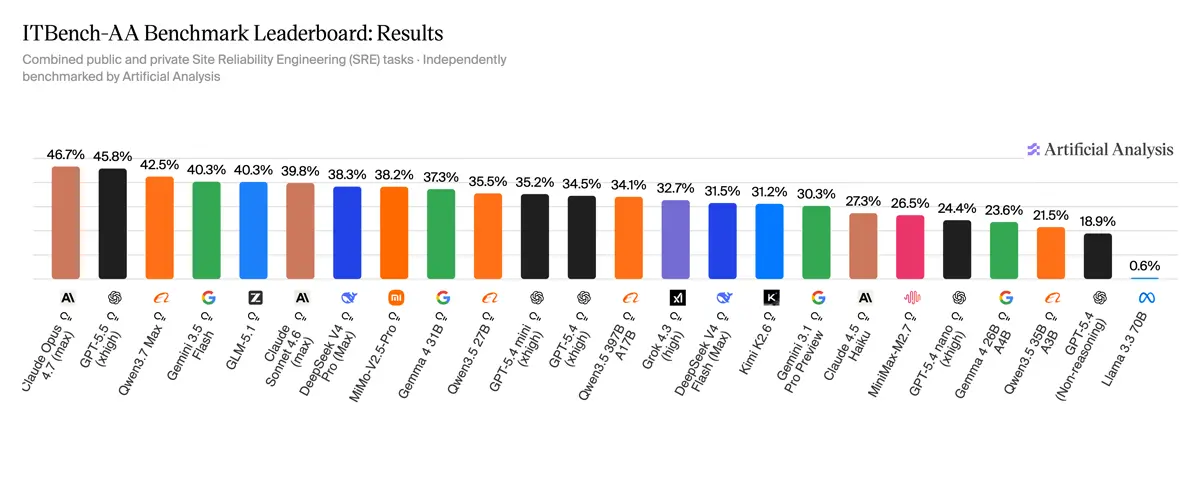
Artificial AnalysisとIBMは2026年5月27日、AIエージェントによる企業IT運用タスクを測る初のベンチマーク「ITBench-AA」をHugging Face Blogで公開しました。まずはSRE(Site Reliability Engineering)領域を対象とし、Kubernetesインシデントの根本原因を特定させるタスクで評価します。最高スコアはClaude Opus 4.7の47%で、全フロンティアモデルが50%未満という、現状もっとも飽和していないエージェントベンチマークの1つになりました。
画像引用元: Hugging Face Blog
何を測るベンチマークなのか
ITBench-AAは、エージェントによる企業IT運用タスクを評価する初のベンチマークと位置付けられています。最初の対象はSRE(Site Reliability Engineering)で、今後はFinOps(財務運用)やCISO(セキュリティ)領域への拡張が計画されています。
中核タスクは、Kubernetesインシデントのスナップショットを診断することです。モデルとエージェントは、ログ・アラート・トレースを読み、複雑なインフラ全体の依存関係を辿り、インシデントの原因となっている最小限の根本原因Kubernetesエンティティ(Deployment、Service、Podなど)を特定する必要があります。
実際のSRE業務に近い設計で、単に「エラーが出ている箇所」を挙げるのではなく、「どのエンティティが真の根本原因か」を構造化されたJSONで提出させる点が特徴です。表面的な症状ではなく、原因の本丸を当てられるかを問う構成になっています。
全フロンティアモデルが50%未満という結果
公開されたリーダーボードでは、プロプライエタリのフロンティアモデルがそろって50%を下回りました。主要な結果は次のとおりです。
- Claude Opus 4.7(Adaptive Reasoning, Max Effort): 47%(1タスクあたり5.38ドル)
- GPT-5.5(xhigh): 46%(平均31ターン)
- Qwen3.7 Max: 42%
- Gemini 3.5 Flash(high): 40%(1.70ドル/タスク)
- Gemini 3.1 Pro Preview: 30%(平均83ターン、2.23ドル/タスク)
オープンウェイトモデルでは、GLM-5.1(Reasoning)が40%(1.23ドル/タスク)、DeepSeek V4 Pro(Reasoning, Max Effort)が38%、Gemma 4 31B(Reasoning)が37%(わずか0.14ドル/タスク)と健闘しています。
多くのフロンティアベンチマークでは上位モデルが70〜90%超を記録するなか、ITBench-AAのSREタスクは全モデルが50%未満。改善余地が大きく残された「未飽和」ベンチマークだという点が、この結果のもっとも重要なメッセージです。
ベンチマークの仕組み
ITBench-AAのSREは合計59タスク(公開40+非公開19)で構成されます。各タスクの入力は、アラート・イベント・トレース・メトリクス・ログ・アプリケーショントポロジを含むKubernetesインシデントのスナップショットです。
エージェントは「Stirrup」というオープンソースの参照ハーネス上で動作し、関連ログやスナップショットを置いたサンドボックス化ファイルシステムへのシェルアクセスを持ちます。1タスクあたり100ターンの上限が設けられ、信頼性確保のため各タスクは3回繰り返されます。
スコアリングには「Average Precision at Full Recall(完全再現時の平均適合率)」が用いられます。モデルが根本原因エンティティをJSONで提出し、IBMが用意した正解集合と比較する仕組みで、ロジックは厳格です。1つでも正解の根本原因を取りこぼすと0.0点になり、すべての正解を当てた場合のみスコアは適合率(TP /(TP + FP))になります。最終スコアは59タスク×3回の平均です。
「すべて当てなければ0点」という再現率ゲート方式が、スコアを押し下げる大きな要因になっています。
「ターン数を増やしても精度は上がらない」
公式が指摘する興味深い発見が、調査の深さと精度が相関しないことです。GPT-5.5(xhigh)は31ターンで46%だったのに対し、Gemini 3.1 Pro Previewは83ターンもかけて30%にとどまりました。
原因は、モデルが過剰に調査することで、上流のメカニズムや同時に発生した症状を「偽陽性(false positive)」として拾ってしまう点にあります。根本原因を網羅しようと深掘りするほど、無関係なエンティティまで根本原因として挙げてしまい、適合率が下がる構造です。
これは実務にも示唆的で、「とにかく長く調べさせる」より「精度高く絞り込ませる」ことの方が重要だという、エージェント設計上の教訓になっています。
コストパフォーマンスとオープンウェイトの健闘
コスト効率の面では、オープンウェイトモデルの存在感が際立ちました。Gemma 4 31Bは0.14ドル/タスクで37%を記録し、2.23ドル/タスクで30%だったGemini 3.1 Pro Previewを上回っています。GLM-5.1(Reasoning)は1.23ドル/タスクで40%と、1.70ドル/タスクのGemini 3.5 Flashに匹敵するコスト効率を示しました。
エンタープライズのSRE運用では、インシデント1件あたりのコストが運用予算に直結します。「高価なフロンティアモデルが必ずしも最良ではない」という結果は、自社のIT運用にエージェントを導入する際のモデル選定に直接効く知見です。
なぜ企業IT運用タスクが難しいのか。公式は、すべての根本原因を特定しなければならない再現率ゲート、過剰調査による偽陽性ペナルティ、Kubernetesインシデント特有の相互依存、最小集合制約、根本原因と相関する障害の切り分け、非構造化ログからの正確なエンティティ特定、の6点を挙げています。ベンチマークの詳細は論文、GitHubリポジトリ、リーダーボードで公開されています。エンジニアにとっては、AIに運用を任せる前に「今のモデルはどこまでできて、どこで間違うのか」を見極める実用的な物差しが、また1つ増えた格好です。

ITBench-AA: Frontier Models Score Below 50% on the First Benchmark for Agentic Enterprise IT Tasks
A Blog post by IBM Research on Hugging Face