0:00 0:00
記事
Hugging Faceが整理した『AIエージェント用語13語』——HarnessとScaffoldの違いを公式定義で読む
Hugging Faceは2026年5月25日、AIエージェントを語るための用語集『Harness, Scaffold, and the AI Agent Terms Worth Getting Right』を公開しました。Harness/Scaffold/Skill/Sub-agentなど13の用語を、Hugging Face公式の定義として整理しています。
Hugging Faceは2026年5月25日、AIエージェント領域で混在しがちな用語を整理する公式ブログ「Harness, Scaffold, and the AI Agent Terms Worth Getting Right」を公開しました。Sergio Paniego氏とAritra Roy Gosthipaty氏が執筆したこの記事は、Harness、Scaffold、Skill、Sub-agentなど13の用語を、Hugging Face公式の定義として整理した実用的な用語集です。
画像引用元: Hugging Face Blog
なぜ「用語の標準化」が必要だったのか
エージェント関連のドキュメントを横断的に読むと、同じ単語が違う意味で使われていたり、別の単語が同じ概念を指していたりする場面によく出会います。たとえば「Agent」が単独のLLMコールを指すのか、ループを持つ自律的なシステムを指すのか、ベンダーや論文ごとに揺れているのが現状です。Hugging Faceは今回、これらの揺れを整理する目的でブログを公開しました。
公式記事ではまず「モデルそのものはエージェントではない」と明示しています。LLMはテキスト入力からテキスト出力を作るだけの存在で、メモリもループも持たない。これにスキャフォールド(足場)とハーネス(実行層)が組み合わさって初めて、ループしながら世界と相互作用するエージェントになるという整理です。
この前提が共有されると、「Claude CodeとCursorで同じモデルを使っても挙動が違う」という日常的な観察が、設計の言語で説明できるようになります。
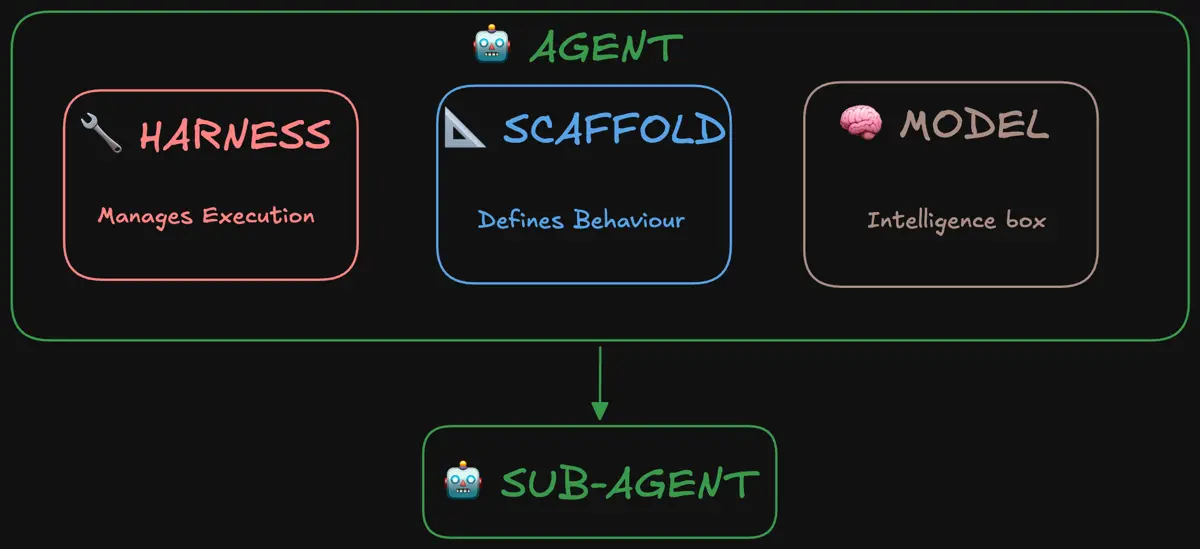
Harness、Scaffold、Modelの三層構造
エージェントを構成する中核として、Hugging Faceは3つの層を提示しています。1つ目が「Model」、LLM本体です。記事ではClaude、Qwen、GPT、Kimi、DeepSeekなどが具体例として挙げられています。
2つ目が「Scaffolding(スキャフォールド)」で、モデルの振る舞いを定義する層です。システムプロンプト、ツールの説明文、出力のパーサ、ステップ間のコンテキスト管理など、モデルが「世界をどう見るか」と「どう動くか」を形作るすべての要素が含まれます。学習段階・推論段階の両方で意味を持つ概念です。
3つ目が「Harness(ハーネス)」で、実際にモデルを呼び、ツール呼び出しを処理し、いつ停止するかを判断する実行層を指します。エラーハンドリングやガードレールの設計を「ハーネスエンジニアリング」と呼ぶことも提案されています。式で書けば「Agent = Model + Harness(+ Scaffolding)」となり、エージェントは観測から行動を返すループ構造として定義されます。
「同じモデルでも別のハーネスに載せれば挙動が変わる」という観察は、この三層構造を意識すると一段クリアに整理できます。
Skill、Sub-agent、Context Engineering——拡張概念の整理
中核三層に加え、運用面で頻出する拡張概念も体系化されています。まず「Tool Use」はAPI、コードインタプリタ、データベース、Web検索、ファイルシステムなど「外部に手を伸ばす経路」を指します。モデルが構造化された意図を表現し、ハーネスがそれを受け取って実際の呼び出しを行う、という分業が明示されています。
「Skill(スキル)」はTool Useの一段上の概念で、複数ステップのタスクをこなすための知識パッケージです。「コマンドを実行する」のがTool、「バグを調査し仮説を立てて修正案を書く」のがSkill、というように、目的達成のための一連の手順をひとまとめにして配布できるものを指します。エージェント間で持ち運び可能で、必要なときにロードして使う設計です。
「Sub-agent(サブエージェント)」は、別のエージェントから呼ばれて子タスクを処理する独立したエージェントを指します。自前のモデルとスキャフォールドを持ち、独立して推論を行い、結果を返す。Tool(関数呼び出し)とSkill(パッケージ化された知識)とは明確に区別され、もう1段階上のモジュール化単位として定義されています。
「Context Engineering」は、ステップごとにエージェントのコンテキストウィンドウに何を入れるかを設計する技術です。短期メモリ(実行中のコンテキスト)と長期メモリ(セッション横断で保持される情報)を分けて扱う点も明記されています。
学習文脈の語彙——Policy、Rollout、Reward
記事の後半は、強化学習由来の語彙の整理に充てられています。「Policy(ポリシー)」は、ある状況においてエージェントがどの行動を取るかの確率分布を指します。重要なのは「ポリシー=エージェントではない」という整理で、ポリシーはモデルの重みと、スキャフォールド・ハーネスの設計の両方から立ち上がる「振る舞いそのもの」だと定義されています。
「RL Environment」は、行動を受け取って状態を更新し、観測を返すステートフルなオブジェクトです。例として「touch foo.txtを実行するとファイル一覧が更新されて返される」というファイルシステム的な環境が挙げられています。「Trainer(トレーナ)」は多数のエピソードを走らせ、スコアを付け、モデル重みを更新する役割で、TRLのGRPOTrainerが具体例として紹介されています。
「Rollout(ロールアウト、別名トラジェクトリ/トレース)」は1回のエピソード全体の記録、「Reward(リワード)」はそのエピソードのスコアです。Rewardは「テストが通る/通らない」のような検証可能(verifiable)な形と、人間の選好やLLM-as-judgeによる学習型の形がある点、エピソード末尾のみのスパース型と各ステップで与えるデンス型がある点も整理されています。Rubric(ルーブリック)を用いて報酬を複数次元に分解する設計も提示されました。
エージェントを訓練する段階に踏み込むと、ここで挙がる語彙は実装に直結するため、用語の不一致が事故を生みやすい領域です。
読者の現場に効く「使い分け」
この用語集は学術的整理にとどまらず、日々のエンジニアリングに直接効く整理が複数含まれています。たとえば自社プロダクトが「LLMラッパー」と呼ばれることに違和感がある場合、それは「Modelをそのまま使っているのではなく、独自のHarnessを設計している」と言語化し直せます。同じく、社内ツールに新しい能力を足すときに「Toolとして実装するのか、Skillとして配るのか、それともSub-agentに切り出すのか」という設計判断が、共通語彙の上で議論できるようになります。
特にClaude Code、Codex、Cursorなどの「コーディングエージェント製品」を比較するときには、製品差をモデル差と勘違いせず、ハーネスとスキャフォールドの設計差として正しく分解することが大切だ、と記事は念を押しています。
Hugging Faceはこの用語集を「生きたドキュメント」と位置づけており、定義に違和感があればGitHub経由でフィードバックを送ってほしいと呼びかけています。明日のチーム会で「ScaffoldとHarnessをどう分けるか」を共通言語で議論できる状態を作るための、実用的なリファレンスとして広く参照されていきそうです。

Harness, Scaffold, and the AI Agent Terms Worth Getting Right
We’re on a journey to advance and democratize artificial intelligence through open source and open science.