0:00 0:00

記事
Hugging FaceがTransformers.jsとGemma 4 E2BをChrome拡張で動かす実装例を公開——Manifest V3/Service Worker/ONNXのフルブラウザ完結
Hugging Faceは2026年4月23日、Transformers.jsとGoogleのGemma 4 E2B(5B、ONNX量子化版)を使って、Chrome拡張をブラウザだけで動かすエージェント実装の解説記事を公開しました。Manifest V3のService Worker構成、IndexedDBベクトル履歴、ツール呼び出し、webMcp正規化レイヤなど、エンドツーエンドの構造が示されています。
ブラウザ完結型のAIエージェントをChrome拡張で組む
Hugging Faceは2026年4月23日、Hugging Face Blogで、Transformers.jsとGemma 4 E2Bを使ったChrome拡張用エージェントの実装解説を公開しました。著者はNico Martin氏で、gemma4-browser-extensionとしてGitHubにソースが公開されています。
ポイントは、モデル推論・ベクトル検索・ツール呼び出しまで、すべてユーザーのブラウザ上で完結する構成になっていることです。サーバーサイドの推論基盤を持たずに、Manifest V3のService WorkerとIndexedDBだけでエージェントの常駐運用を成立させているのが特徴です。
画像引用元: Hugging Face Blog
使われているモデルとランタイム
記事で扱われている主要なモデルは次の3つです。すべてONNX化されたバージョンを利用し、Transformers.js経由でブラウザ上で実行します。
| モデル | 用途 | 配置 |
|---|---|---|
| google/gemma-4-E2B | テキスト生成(5Bパラメータ) | Background Service Worker |
| onnx-community/gemma-4-E2B-it-ONNX | 推論最適化済みinstruct版 | Background Service Worker |
| onnx-community/all-MiniLM-L6-v2-ONNX | ベクトル埋め込み(セマンティック検索) | Background Service Worker |
Transformers.jsは、Pythonのtransformersと互換のあるAPIをJavaScriptで提供するライブラリで、ブラウザ上でモデルをロード・推論できる仕組みです。Service Worker側で推論を担う設計にすることで、UI側のスレッドを軽量に保ちつつ、複数のタブ/コンポーネントから同じモデルセッションを共有できる構成になります。
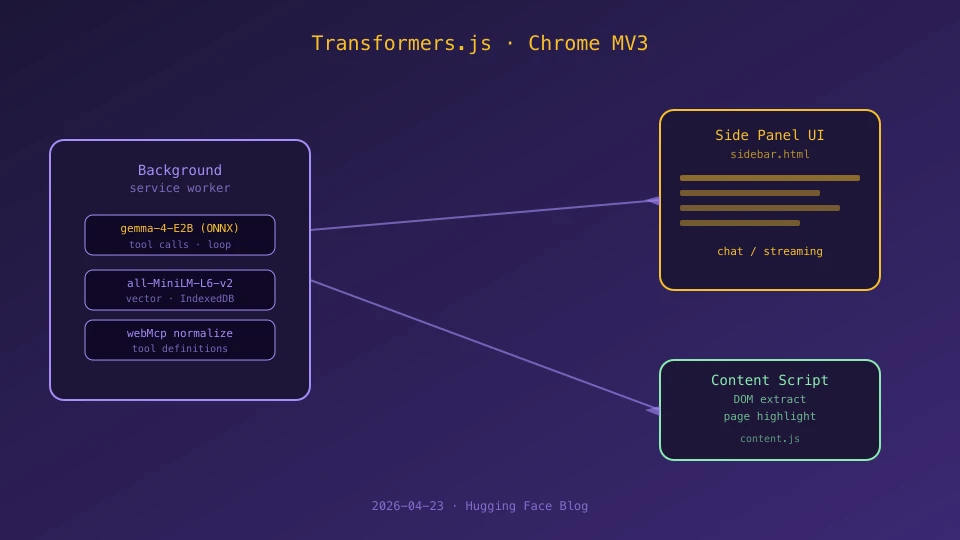
Manifest V3を活用した3層構成
Chrome拡張のManifest V3は、Background Service Worker/Side Panel UI/Content Scriptという3層構成が基本です。今回のエージェントもこの構成を踏襲しつつ、それぞれの責務を明確に分離しています。
Background Service Worker(background.js)
エージェントのオーケストレーション・モデル推論・ライフサイクル管理を担当します。AGENT_INITIALIZE/AGENT_GENERATE_TEXT/AGENT_GET_MESSAGES/AGENT_CLEARといったメッセージで、UI側からの要求を受けつけます。Service Workerの寿命管理を意識して、状態の永続化はIndexedDBやchrome.storageに分散させているのが実装上の工夫です。
Side Panel UI(sidebar.html)
ユーザーが直接操作するチャットUIです。ストリーミングのトークンをBackgroundから受け取り、リアルタイムに表示します。内部のモデル対話履歴と、ユーザーに見せるチャットメッセージを別管理にしている点もポイントで、ツール呼び出しの中間表現がそのまま表示に出ない設計です。
Content Script(content.js)
ページのDOMアクセス、ページ内容抽出、要素ハイライトを担います。BackgroundからEXTRACT_PAGE_DATA/HIGHLIGHT_ELEMENTS/CLEAR_HIGHLIGHTSといったコマンドを受けて動作する形です。ページごとの抽出結果はBackground側でURLをキーにしたキャッシュに保存され、再訪問時のレスポンスを高速化しています。
ツール呼び出しと「webMcp」正規化
エージェントの肝はツール呼び出しです。記事では、スキーマで定義されたツールをモデルが呼び出し、Background側で実行する標準的なパターンが採用されています。注目したいのは**webMcpという正規化レイヤ**で、ツール定義のフォーマットを揃えて拡張側のツールエコシステムを取り回しやすくしている点です。
「内部の対話ログ(モデルが見ている全文)」と「UIに見せる対話履歴」を分けて管理し、ツール呼び出しが裏で何回起きてもユーザーには中間結果が表示されないようになっています。これは、エージェント実装で**「ユーザー体験のクリーンさ」と「モデル側の文脈の豊かさ」を両立する**ための定番パターンです。
ストレージの使い分け
ストレージは目的別に明確に分離されています。
| 用途 | 保存先 |
|---|---|
| 対話状態 | Background memory(高速オーケストレーション) |
| ツール環境設定 | chrome.storage.local |
| ベクトル履歴 | IndexedDB(セマンティック検索) |
| ページ抽出 | Background URL別キャッシュ |
特にIndexedDBによるベクトル履歴は、セマンティック検索で過去の対話・閲覧ページを文脈として呼び戻す要になっています。all-MiniLM-L6-v2の埋め込みをローカルで作り、ローカルDBで検索する完全オフライン構成です。
必要な権限と展開
Chrome拡張に必要なpermissionsは以下のとおりです。
{
"permissions": ["sidePanel", "storage", "scripting", "tabs"],
"host_permissions": ["http://*/*", "https://*/*"]
}任意のページに対してDOMアクセスする想定の構成ですが、モデル推論はすべてローカルなので、ページ内容が外部サーバーに送られない点はプライバシー観点で重要です。エンタープライズ環境への配布や、社内規定の厳しい組織での導入を考える際にも、**「ページ内容がHugging Faceや任意のクラウドに行かない」**ことは大きな差別化要素になります。
実機の動作確認には、Chrome Web Storeに公開されている拡張、またはGitHubリポジトリから直接ロードする2通りが用意されています。
エンジニア視点の見どころ
ブラウザ完結型のエージェントは、コストとプライバシーの両面で魅力があります。サーバー側で推論基盤を保つコストが不要で、ユーザーデータがローカルから出ません。一方で、初回のモデルダウンロード時間(数百MB〜GB級)とユーザーマシンのスペック依存は実運用上の課題です。
実装で参考になるポイントは次の3点です。
- Manifest V3のService Worker寿命を前提に、状態をIndexedDBや
chrome.storageへ分散 - 対話履歴のUI/モデル分離で、ツール呼び出しの中間結果をユーザーから隠す
- ベクトル履歴をブラウザDBで持つことで、ローカルで成立するRAGを構築
このパターンは、社内向けユーティリティツールや、特定SaaSのページ操作補助エージェントなど、用途を絞った軽量エージェントで再利用しやすい構成です。
今週のオンデバイス/ブラウザAIとの位置づけ
直前にはHugging FaceがGemma 4 VLAをJetson Orin Nano Superで動かすデモも公開されています。ブラウザとエッジ端末の両方で、Gemma 4ベースのエージェントが動く形が示された格好で、サーバーレスでAIアプリを組む選択肢が確実に広がってきています。

How to Use Transformers.js in a Chrome Extension
We’re on a journey to advance and democratize artificial intelligence through open source and open science.