0:00 0:00

記事
IBM、200言語対応の埋め込みモデル「Granite Embedding R2」をApache 2.0で公開——97MモデルでもMTEB Multilingual Retrieval 60.3点
IBMは2026年5月14日、Hugging Face上でオープン埋め込みモデル「Granite Embedding Multilingual R2」を公開しました。97Mと311Mの2サイズで200言語以上に対応し、コンテキスト長は32,768トークン。Apache 2.0ライセンスで商用利用可能で、97MモデルでもMTEB Multilingual Retrievalスコア60.3点と、3倍規模の従来モデルを上回る性能を示しています。
IBMは2026年5月14日、Hugging Faceのブログとモデルハブ上で、オープンソースの埋め込みモデル「Granite Embedding Multilingual R2」を公開しました。97Mと311Mの2サイズが用意され、いずれも200言語以上に対応、コンテキスト長は32,768トークン、ライセンスは商用利用可能なApache 2.0です。MS-MARCOデータセットを使わずに訓練しているため、ライセンス制約の心配なく企業利用できる点も特徴とされます。
画像引用元: Hugging Face Blog
「サブ100Mで最高のRetrieval品質」と公式が主張
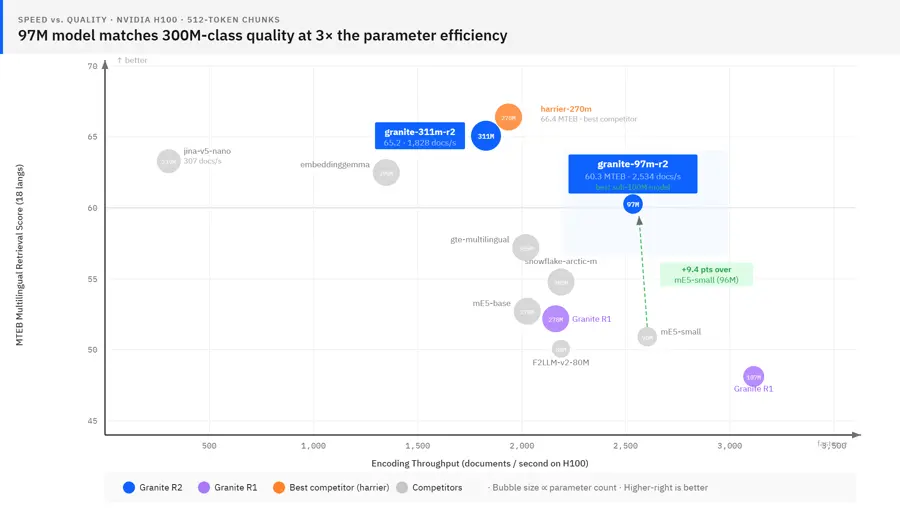
IBM Graniteチームの発表によると、97Mパラメータ版「granite-embedding-97m-multilingual-r2」は、サイズが3倍の従来モデル群を上回る検索品質を達成しています。MTEB Multilingual Retrievalスコアは60.3点、コードRetrievalは60.4点、英語Retrievalは50.1点、長文ベンチマークLongEmbedで65.6点という数値が示されています。
311M版「granite-embedding-311m-multilingual-r2」はさらに高く、MTEB Multilingual 65.2(公開モデル中2位)、LongEmbed 71.7(1位)と案内されています。R1世代の107M版と比較すると、Multilingual Retrievalスコアは48.1から60.3への大幅な伸びで、世代交代と表現しても過言ではない差です。
32Kコンテキスト・200言語・Matryoshkaサポート
R2世代の大きな変更点は、コンテキスト長が512トークンから32,768トークンへ64倍に拡張されたことです。長い社内ドキュメントやマニュアルをそのまま埋め込みできる範囲が広がり、RAG構築時のチャンク分割設計の自由度が増しています。
311Mモデルは「Matryoshka」次元削減もサポートしており、768次元から512・384・256・128へ切り詰めて使えます。これは、ベクトルストアの容量と検索精度のトレードオフをデプロイ時に調整できる仕組みで、規模が大きいRAG環境で運用コストを下げる選択肢として案内されています。
| モデル | 総パラメータ | アクティブ | 次元 | コンテキスト |
|---|---|---|---|---|
| granite-embedding-97m-r2 | 97M | 28M | 384 | 32,768 |
| granite-embedding-311m-r2 | 311M | 110M | 768 | 32,768 |
スピード重視の運用も視野に
IBM Graniteチームは推論速度の数値も示しており、97MモデルはNVIDIA H100 GPUで毎秒2,500件以上のドキュメントを処理できると案内しています。311Mモデルでも毎秒約1,800件と、本番運用に十分な速度水準です。アクティブパラメータ数を絞ったMoE的な設計が効いており、サイズの割に動作が軽い点が強調されています。
コード検索の対応言語は9つ(Python、Java、JavaScript、Go、Rust、C++、TypeScript、PHP、Ruby)で、社内コードベースの検索やコードドキュメントRAGに使える形に整理されています。多言語性能と合わせて、IBM Graniteチームは「英語+日本語+ヨーロッパ言語が混在する企業ドキュメント」のような実務シナリオを意識していると読み取れます。
エコシステム対応:主要フレームワーク横並び
Granite Embedding R2は公開時点で、sentence-transformers、LangChain、LlamaIndex、Haystack、Milvusなど主要なRAGフレームワークに対応していると案内されています。デプロイ面でも、ONNX、OpenVINO、vLLM、Ollama経由でのサーブが可能です。
特にOllama経由でローカル実行できる点は、機密データを外部APIに渡したくない企業利用にとって重要です。RAGの埋め込みステップをクラウドAPIからローカルモデルに置き換える際の、有力な選択肢の一つになります。Apache 2.0ライセンスは商用利用や再配布も明示的に許可しており、IBMが「企業向けのオープン埋め込み基盤」を狙っていることが明確です。
公開モデルとして注目すべき位置づけ
Granite Embedding R2は、検索品質の数値、ライセンス、コンテキスト長、エコシステム対応のいずれも実務寄りの設計が目立つモデルです。公式ベンチマークの数値は、multilingual-e5-small(MTEB Multilingual 50.9)やparaphrase-multilingual-MiniLM-L12-v2(同36.6)といった既存の人気モデルと比較しても明確に上回っており、置き換え対象として現実的です。
ただし、ベンチマークスコアはあくまで公式公開値であり、実際の業務データでの精度は対象ドメインに依存します。日本語が混在するRAG用途では、自社のドキュメントで小さな評価セットを用意し、既存の埋め込みモデルとR2の双方を試して相対比較するのが現実的な導入手順です。Apache 2.0で配布されているため、評価から本番移行までの法務的な障壁は低く、まずは97M版を試して感触を見るアプローチが取りやすいリリースといえます。

Granite Embedding Multilingual R2: Open Apache 2.0 Multilingual Embeddings with 32K Context — Best Sub-100M Retrieval Quality
A Blog post by IBM Granite on Hugging Face