0:00 0:00

記事
NVIDIA、自己回帰と拡散を切り替えられる「Nemotron-Labs Diffusion」を公開。8Bモデルで最大6.4倍のトークン効率
NVIDIAは2026年5月23日、Hugging Face上でNemotron-Labs Diffusion言語モデル群(3B/8B/14B)を発表しました。同じチェックポイントから自己回帰・拡散・自己投機の3モードを切り替えて推論できる設計で、8Bモデルでは拡散モードでAR比2.6倍、線形自己投機で6.0倍、二次自己投機で6.4倍のフォワードパスあたりトークン数を達成したとしています。
NVIDIAは2026年5月23日、Hugging Face Blog上で「Nemotron-Labs Diffusion」と呼ばれる拡散言語モデル群を発表しました。同じモデルチェックポイントから自己回帰・拡散・自己投機の3つのモードを切り替えて推論できる設計が特徴で、レイテンシ重視のアプリケーションでGPUの計算リソースをより活かせるとしています。
画像引用元: Hugging Face Blog
なぜ拡散言語モデルなのか
NVIDIAはまず、現在の大規模言語モデルが抱える構造的な制約を整理しています。多くのLLMは依然として1トークンずつ順に生成し、後続トークンが先行トークンに依存する**自己回帰(AR)**モデルです。ARは学習が安定でサーバ実装も単純な反面、1トークンごとにモデルの重み全体を読み出す必要があるため、メモリ操作に時間を取られ、計算リソースを使い切れない場面があるとしています。
加えて、自己回帰モデルでは一度生成したトークンを後から書き換える仕組みを持たないため、生成途中で発生した誤りがそのまま下流に伝搬しやすい弱点もあるとNVIDIAは指摘しています。
3Bから14BまでのモデルとデュアルAR+拡散学習
Nemotron-Labs Diffusionは、テキストモデルとして3B・8B・14Bの3サイズで公開されています。NVIDIAは、自己回帰と拡散の生成は別々のモデルファミリではなく、同じモデルが持つ能力として統合されるべきだという設計思想に基づいているとしています。
この実現のために、Nemotron-Labs Diffusionは既存のARモデルに拡散能力を追加する学習方針を採用しています。学習はARと拡散の共同目的で行われており、ARで獲得した能力を保ちながら、拡散による並列ドラフト能力を後付けする形です。事前学習は1.3T(1.3兆)トークンで実施されたとされています。
自己回帰・拡散・自己投機の3モード
Nemotron-Labs Diffusionが提供する3つの推論モードは、デプロイ時の設定で切り替えられる仕組みです。アプリケーションコード側の変更はほぼ不要で、同じチェックポイントを3通りの推論方法に振り分けられます。
- Autoregressive mode:1トークンずつ左から右に生成する、既存のARモデルと互換の動作
- Diffusion mode:複数のトークンを同時にマスク・予測する並列生成
- Self-speculation:拡散による下書きをARで検証して採用する自己投機デコード
特にバッチサイズ1のような小バッチでも、メモリ帯域に律速されにくい挙動が期待でき、レイテンシ重視のワークロードに向くとNVIDIAは説明しています。
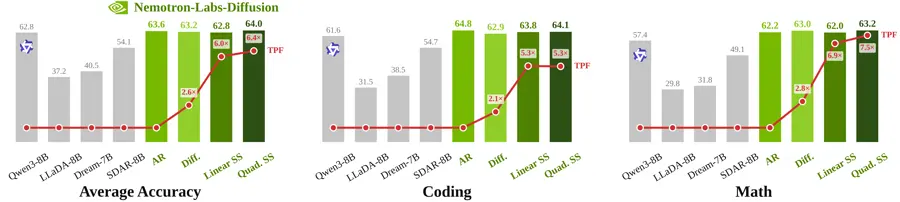
8Bモデルの精度と速度の数値
NVIDIAが公表している8Bモデルの数値は、Qwen3 8B比で平均精度が1.2%高いとされています。推論効率はトークン毎フォワードパス数(TPF)というハードウェアに依存しない指標で比較されており、次のような結果が示されています。
- 拡散モード:ARの2.6倍のTPF
- 線形の自己投機:6.0倍のTPF
- 二次の自己投機:6.4倍のTPF
NVIDIAは、評価したタスク全体で精度はほぼ同等であり、速度向上が精度の犠牲なしに達成できているとしています。これまで拡散言語モデルが抱えていた「強いARモデルに比べて精度が落ちる」「KVキャッシュとの相性が悪い」といった実用上の壁を、AR互換のチェックポイントに拡散能力を追加するアプローチで突破した形です。
SGLangでの推論サポート
デプロイ面では、SGLangのメインブランチで近日中にサポートされる予定だと案内されています。記事執筆時点でも推論は利用可能で、開発者は同じチェックポイントを3つのモードのいずれでも提供できるため、設定ファイルの1行を変えるだけで挙動を切り替えられるとしています。
NVIDIAは、拡散モデルが実用的に使える形でAR互換のエコシステムに入ってきたことで、開発者はテキストを「下書き・洗練・検証・加速」する新しい手段を得ると整理しています。アプリケーション側の作り直しを前提にしない設計が、採用のハードルを下げそうです。
まとめ:「同じモデルで3通りに動かせる」設計
Nemotron-Labs Diffusionは、自己回帰モデルから完全に離れて拡散モデルへ振り切るのではなく、両者を1つのモデルに統合する道を選んでいます。AR互換を維持しつつ、必要に応じて拡散や自己投機に切り替えてスループットを引き上げられる構造です。
レイテンシに厳しいエージェント用途や、バッチサイズが揃いにくい現場では、TPFの数倍向上が体感速度に直結する可能性があります。モデルそのものはHugging Faceで公開されており、3B〜14Bのサイズ展開も含めて、自社用途での比較検証がしやすい構成になっています。

Towards Speed-of-Light Text Generation with Nemotron-Labs Diffusion Language Models
A Blog post by NVIDIA on Hugging Face