0:00 0:00

記事
NVIDIA、GPU間帯域を測る公式ツール「NVbandwidth」を解説——NVLinkからPCIe、マルチノードまで
NVIDIAはCUDAベースのベンチマークツール「NVbandwidth」を紹介する解説記事を公開しました。CPU-GPU間やGPU間、さらにはマルチノード構成の帯域・レイテンシを一貫した方法で計測できると案内しています。
GPUの本気を引き出すには「帯域」がボトルネック
NVIDIAは2026年4月14日、CUDA Performanceチームの解説記事として、GPU間およびメモリ間の帯域を計測する公式ツールNVbandwidthの使い方と設計思想を公開しました。現代のGPUは計算性能こそ飛躍的に伸びているものの、デバイス間でデータをいかに速く動かせるかが実行時性能を決めているという問題意識が、記事の出発点になっています。
解説では、AIやHPCのワークロードで複数GPUやマルチノードを組んだときに「計算は空いているのに転送待ちで進まない」という典型的なボトルネックを特定するには、標準化されたベンチマークが不可欠だと強調されています。NVbandwidthはまさにその目的のために設計されたツールで、同社は性能最適化や不具合切り分けのための基本装備として位置づけています。
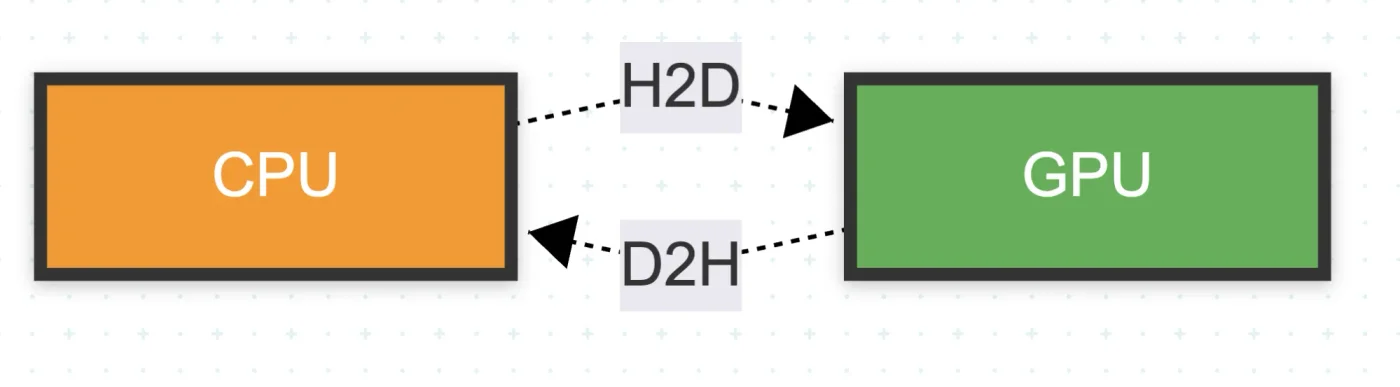
画像引用元: NVIDIA Developer Blog
単方向・双方向・マルチGPU・マルチノードを一気通貫で計測
NVbandwidthの特徴は、計測シナリオの網羅性にあります。CPUからGPUへのコピー(H2D)、GPUからCPUへのコピー(D2H)、GPU同士のコピー(D2D)という基本パターンに加え、単方向・双方向、さらにはマルチGPUやマルチノードまで同じツールで計測できるようになっています。
転送方式についても、Copy Engine(CE)を使う方法とストリーミングマルチプロセッサ(SM)上のカーネルを使う方法の両方に対応しており、どちらがワークロードにとって適切かを実測で比較できる構成です。相互接続はNVLink、NVLink C2C、PCIeといった異なる種類に対応し、明示的にトポロジーを指定しなくても動作するため、手元のシステムで「とにかく測って違いを見る」ユースケースに向きます。出力はプレーンテキストとJSONの両方から選べ、既存のダッシュボードや自動化パイプラインに取り込みやすい設計です。
測定手法はスピンカーネルでキュー投入の誤差を排除
記事では計測精度を支える実装の工夫にも触れています。NVbandwidthは、ホストメモリ上のフラグをスピン待機するカーネルをあらかじめキューに積んでおき、そのカーネルをトリガーにして実際の転送を開始する方式を採用しているとされています。これにより、CUDAのキュー投入に要する時間を転送測定から除外し、転送そのものの純粋な帯域を記録できるようにしているとのことです。
この設計のおかげで、短時間・小サイズの転送でも安定した測定結果が得られ、GPUアップグレードやドライバーアップデート後のリグレッション検出にも向くと案内されています。アーキテクチャ的にはCLI、テストケースフレームワーク、メモリコピーフレームワーク、出力モジュールが分離されており、独自のテストケースを追加する拡張性も意識した作りになっています。
マルチノード対応とCUDA 12.3以降での新機能
マルチノード環境での計測は、CUDAツールキット12.3以降とNVIDIA Internode Memory Exchange Service(IMEX)、そしてMPIによる調整が前提になるとNVIDIAは案内しています。NVSwitchを介して接続されたNVIDIA Multi-Node NVLinkシステムにおいて、複数GPU間の帯域を実測で把握できるのは、大規模AIクラスタの設計と運用で重要な意味を持ちます。
単ノード用途であればCUDA 11.X以降、C++17対応のGCC 7.x以降、CMake 3.20以降といった一般的な開発環境で動作し、ハードウェア導入後の受け入れテストや、CI上でのリグレッションチェックにも組み込みやすい構成です。NVIDIAはNVbandwidthを、CUDAアプリケーションの性能プロファイリングと問題切り分けのための基盤ツールとして位置づけており、GPUを前提としたシステム設計に関わる開発者にとっては、手元に置いておく価値の大きいユーティリティだといえます。

NVIDIA NVbandwidth: Your Essential Tool for Measuring GPU Interconnect and Memory Performance
When you’re writing CUDA applications, one of the most important things you need to focus on to write great code is data transfer performance. This applies to both single-GPU and multi-GPU systems…