0:00 0:00

記事
NVIDIAがMegatronでMuonなど新世代オプティマイザを公開——GB300 256基でKimi K2学習がAdamW比1,080 TFLOPs/sに
NVIDIAは2026年4月22日、開発者ブログでMegatron向けの新オプティマイザ群を公開しました。Muon(MomentUm Orthogonalized by Newton-Schulz)をKimi K2とQwen3 30B-A3Bに適用し、AdamW比で学習スループットが向上した結果を報告しています。NeMo Megatron Bridge 26.02と連携する構成です。
Megatronに加わる新世代オプティマイザ
NVIDIAは2026年4月22日、NVIDIA Developer Blogで、大規模言語モデル学習フレームワークMegatron向けに実装された新世代のオプティマイザ群を公開しました。記事の中心はMuon(MomentUm Orthogonalized by Newton-Schulz)と、それに連なる高次オプティマイザの系譜で、一次最適化のAdamWだけでは取り切れない学習効率を狙う位置づけになっています。
成果はNVIDIA/NeMo Megatron Bridge 26.02、Megatron Core、そして新設されたNVIDIA-NeMo/Emerging-Optimizersリポジトリに取り込まれており、エンドユーザーがバージョン指定で試せる状態で提供されます。
画像引用元: NVIDIA Developer Blog
Muonがやっている工夫
Muonは、勾配モメンタムの更新をNewton-Schulz反復で近似的に直交化することで、層ごとの更新方向をならそうとするオプティマイザです。従来のAdamWのような要素単位の適応学習率ではなく、行列としての更新方向を直交化することで、大規模モデルで起きやすいパラメータ間の不均衡を緩和できる点が特徴とされています。
Newton-Schulz反復は行列平方根の反復近似としてよく知られた手法ですが、ここでは学習ループの毎ステップの中にコンパクトに組み込める形で実装されている点が実装上のポイントです。Megatron側の分散通信レイヤとも整合する形で実装され、テンソル並列・パイプライン並列との併用でもスケールするよう設計されています。
Kimi K2とQwen3 30B-A3Bでの計測結果
NVIDIAが公開したベンチマーク結果は次の通りです。
| モデル | オプティマイザ | スループット(TFLOPs/s/GPU) | ハードウェア |
|---|---|---|---|
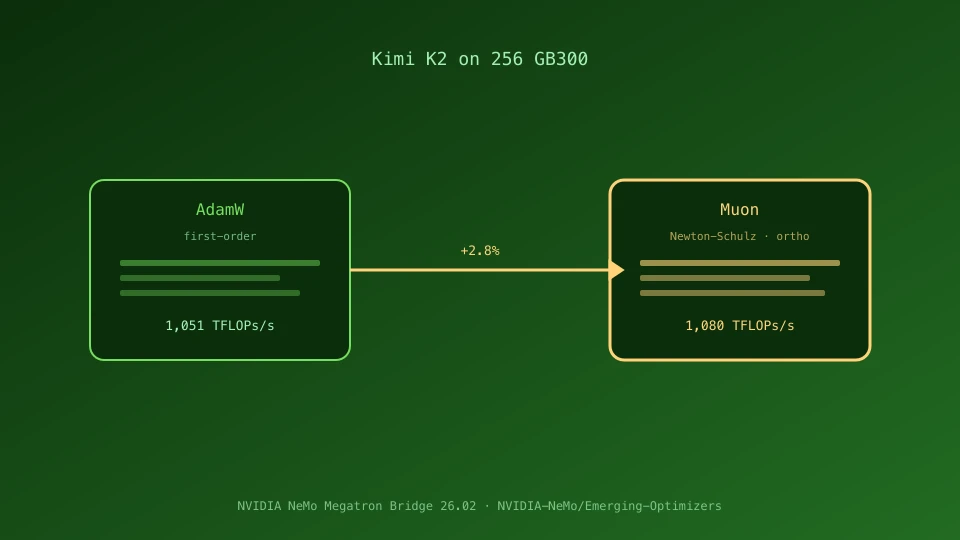
| Kimi K2 | AdamW | 1,051 | GB300 × 256基 |
| Kimi K2 | Muon | 1,080 | GB300 × 256基 |
| Qwen3 30B-A3B | AdamW | 713 | GB300 × 8基 |
| Qwen3 30B-A3B | Muon | 721 | GB300 × 8基 |
Muon適用によるスループット差は数%の微増に留まりますが、記事では**「very small training performance loss using the Muon optimizer compared to AdamW」**と整理されており、精度面でのペナルティがほぼ無い形で速度を確保している点がポイントになります。単純にモデル収束が速くなるという話ではなく、大規模分散環境で計算資源を無駄なく使い切れる構成としての意味合いが強い内容です。
GB300での検証とスケール観
検証に使われたGB300は、2026年時点のNVIDIAデータセンター向けフラッグシップ構成です。Kimi K2のような超大規模モデルを256基のGB300で動かした際に、AdamWとMuonの差がどう出るかを計測しており、小規模実験では見えにくい差を、そのままプロダクション規模で提示した点に目が行きます。
Qwen3 30B-A3Bのような30Bパラメータ級でも同様の傾向が確認されたことは、Muonが超大規模専用の話ではなく、中規模から大規模の連続スペクトルで使えることを示しています。実装を触るエンジニア目線では、手元で試す場合もNeMoとMegatron Core側のアップデートで自然に取り込める経路が用意されています。
Emerging-Optimizersリポジトリでの扱い
NVIDIAは今回、単一のオプティマイザ追加ではなく、高次・実験的オプティマイザを継続的に検証する器としてNVIDIA-NeMo/Emerging-Optimizersを公開しています。ここにはShampooなど、これまで「研究発表はされているが大規模で現実的に動かす実装が限られていた」系のオプティマイザも、Megatron分散環境向けに整えた形で入る見込みです。
一次情報の段階では具体的なリリースカレンダーは示されていませんが、Megatron Bridge 26.02を入口に、今後のオプティマイザ追加もMegatron側のアップデートとして配布されるという運用が見えます。研究側の論文と本番側のフレームワークを、NVIDIA公式がマージしていく動きとして読むと分かりやすい内容です。
エンジニア視点でどう使うか
実務観点では、既にAdamWで学習ループを組んでいるチームが、コードのごく一部の差し替えでMuonを試せるように整備されていることが重要です。NeMoやMegatron Coreの設定層でオプティマイザを切り替える構成になっているため、ハイパーパラメータ探索の一軸としてMuonを乗せるような使い方が現実的です。
一方で、今回公開された数字は1イテレーションあたりのスループット向上が中心で、損失収束・downstream性能に関する長期ベンチマークは追加記事や論文を待つ形になります。チューニング対象として採用する際は、NVIDIAが示すスループット差だけを根拠にせず、自分のモデル・データで学習曲線と評価指標の両方を追うのが安全です。
今週のNVIDIA系アップデートとの関係
同じ週には、NVIDIAとGoogle CloudがRubin世代GPUで提携を拡大し、Google Cloud Next 2026でGemini Enterprise Agent Platformも発表されています。大規模学習ハードとオプティマイザが同時に刷新される流れの中で、Megatron側の改善もタイミングを合わせて公開された形になります。

Advancing Emerging Optimizers for Accelerated LLM Training with NVIDIA Megatron
Higher-order optimization algorithms such as Shampoo have been effectively applied in neural network training for at least a decade. These methods have achieved significant success more recently when…